This post originally appeared on the Digital Humanities at Berkeley blog. It is the first in what became an informal series. For a brief reflection on the development of that project, see the more recent post, Reading Distant Readings.
Computers are basically magic. We turn them on and (mostly!) they do the things we tell them: open a new text document and record my grand ruminations as I type; open a web browser and help me navigate an unprecedented volume of information. Even though we tend to take them for granted, programs like Word or Firefox are extremely sophisticated in their design and implementation. Maybe we have some distant knowledge that computers store and process information as a series of zeros and ones called “binary” – you know, the numbers that stream across the screen in hacker movies – but modern computers have developed enough that the typical user has no need to understand these underlying mechanics in order to perform high level operations. Somehow, rapid computation of numbers in binary has managed to simulate the human-familar typewriter interface that I am using to compose this blog post.
There is a strange disconnect, then, when literature scholars begin to talk about using computers to “read” books. People – myself included – are often surprised or slightly confused when they first hear about these kinds of methods. When we talk about humans reading books, we refer to interpretive processes. For example, words are understood as signifiers that give access to an abstract meaning, with subtle connotations and historical contingencies. An essay makes an argument by presenting evidence and drawing conclusions, while we evaluate it as critical thinkers. These seem to rely on cognitive functions that are the nearly exclusive domain of humans, and that we, in the humanities, have spent a great deal of effort refining. Despite the magic behind our normative experience of computers, we suspect that these high-level interpretive operations lie beyond the ken of machines. We are suddenly ready to reduce computers to simple adding machines.
In fact, this reduction is entirely valid – since counting is really all that’s happening under the hood – but the scholars who are working on these computational methods are increasingly finding clever ways to leverage counting processes toward the kinds of cultural interpretation that interest us as humanists and that help us to rethink our assumptions about language.
SO HOW DO COMPUTERS READ?
Demystifying computational text analysis has to begin with an account of its reading practices, since this says a great deal about how computers interpret language and what research questions they make possible. At the moment, there are three popular reading methods used by humanists: bag of words, dictionary look-up, and word embeddings.
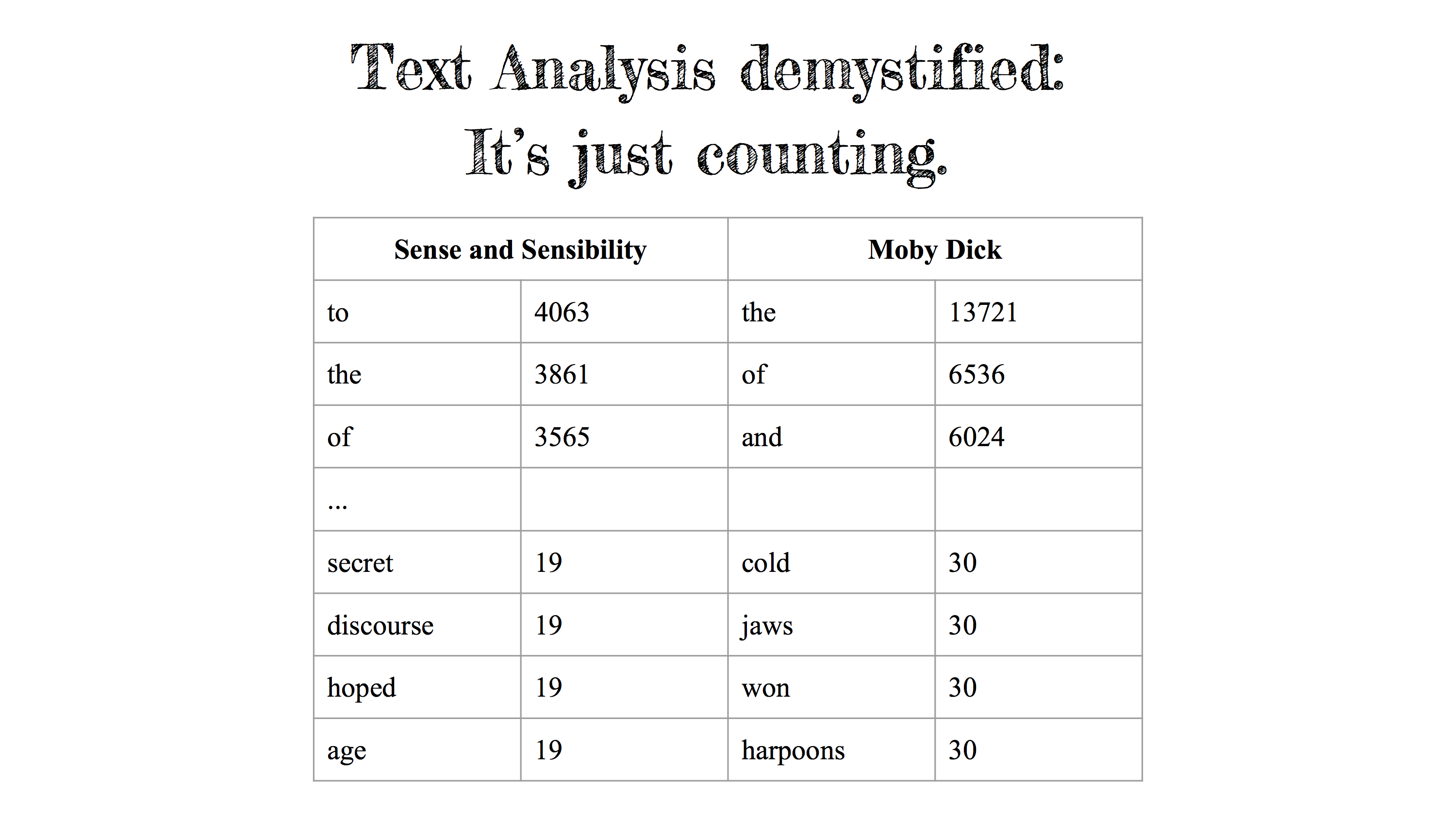
Far and away, the most common of these is the bag of words. This is the tongue-in-cheek name for the process of counting how many times each word in a text actually appears. By this approach Moby Dick consists of the word the 13,721 times, harpoons 30 times, etc. All information about word-order and usage have been stripped away, and the novel itself is no longer human readable. Yet these word frequencies encode a surprising degree of information about authorship, genre, or even theme. If humanists take it as an article of faith that words are densely complex tools for constructing and representing culture, then the simple measurement of a word’s presence in a text appears to capture a great deal of that.
While the vanilla bag-of-words approach eschews any prior knowledge of words’ semantic meanings, dictionary look-ups offer a strategy to re-incorporate that to an extent. In this context, a “dictionary” refers to a set of words that have been agreed before hand to have some particular valence – sometimes with varying degrees. For example, corpus linguists have drawn up lists of English words that indicate reference to concrete objects versus abstract concepts or positive versus negative emotions. Although the computer is not interpreting words semantically, it is able to scan a text to find words that belong to dictionaries of interest to the researcher. This can be a relatively blunt instrument – which justifiably leads humanists to treat it with suspicion – yet it also offers an opportunity to bring our own interpretative assumptions to a text explicitly through dictionary construction and selection. We are not looking at the signifiers themselves, so much as some facet(s) of their abstract signification.
And whereas bag of words had eliminated information about context, word embedding inverts this approach by considering how words relate to one another precisely through shared context. Imagine that each word in a novel has its meaning determined by the ones that surround it in a limited window. For example, in Moby Dick‘s first sentence, “me” is paired on either side by “Call” and “Ishmael.” After observing the windows around every word in the novel (or many novels), the computer will notice a pattern in which “me” falls between similar pairs of words to “her,” “him,” or “them.” Of course, the computer had gone through a similar process over the words “Call” and “Ishmael,” for which “me” is reciprocally part of their contexts. This chaining of signifiers to one another mirrors some of humanists’ most sophisticated interpretative frameworks of language.
Word embedding has only just recently begun to be used by humanists, however they are worth mentioning because their early results promise to move the field ahead greatly.
BUT HOW DO YOU USE THESE IN ACTUAL RESEARCH?
The difficult and exciting part of any research project is framing a question that is both answerable and broadly meaningful. To put a fine point on it, our counting machines can answer how many happy and sad words occur in a given novel, but it is not obvious why that would be a meaningful contribution to literary scholarship. Indeed, a common pitfall in computational text analysis is to start with the tool and point it at different texts in search of an interesting problem. Instead, to borrow Franco Moretti’s term, digital humanists operationalize theoretical concepts – such as genre or plot or even critical reception – by thinking explicitly about how they are constructed in (or operate on) a text and then measuring elements of that construction.
For instance, in the study of literary history, there is an open question regarding the extent of the “great divide” between something like an elite versus a mainstream literature. To what extent do these constitute separate modes of cultural production and how might they intervene on one another? Ted Underwood and Jordan Sellers tried to answer one version of this question by seeing whether there were differences in the bag of words belong to books of poetry that were reviewed in prominent literary periodicals versus those that were not. After all, the bag of words is a multivalent thing capturing information about style and subject matter, and it seems intuitive that critics might be drawn to certain elements of these.
In fact, this turned out to be the case, but even more compelling was a trend over the course of the nineteenth century, in which literature overall – both elite and mainstream – tended to look more and more like the kinds of books that got reviews earlier in the century. This, in turn, raises further questions about how literary production changes over time. Perhaps most importantly, the new questions that Underwood and Sellers raise do not have to be pursued necessarily by computational methods but are available to traditional methods as well. Their computationally grounded findings contribute meaningfully to a broader humanistic discourse and may be useful to scholars using a variety of methods themselves. Indeed, close reading and archival research will almost certainly be necessary to account for the ways literary production changed over the nineteenth century.
Of course, the measurement of similarity and difference among bags of words that underpins Underwood and Sellers’ findings requires its own statistical footwork. In fact, one way to think about a good deal of research in computational text analysis right now is that it consists of finding alternate statistical methods to explore or frame bags of words in order to operationalize different concepts. On the other hand, no particular measurement constitutes an authoritative operationalization of a concept but is conditioned by its own interpretive assumptions. For instance, the question of elite versus mainstream literature was partly taken up by Mark Algee-Hewitt, Sarah Allison, Marissa Gemma, Ryan Heuser, Franco Moretti, and Hannah Walser in their pamphlet, “Canon/ Archive. Large-Scale Dynamics in the Literary Field.” (See the summary and relevant graph in this pamphlet.) However they take a radically different approach from Underwood and Sellers, by framing the problem as one of linguistic complexity rather than subject matter.
Perhaps, then, we can take this as an invitation to collaborate with colleagues across the disciplinary divide. As humanists we have intensely trained to think about interpretive frameworks and their consequences for cultural objects. And in statistics and computer science departments are experts who have trained in powerful methods of measurement. Operationalizing our most closely-held theoretical concepts like plot or style does not have to be reductive or dry in the way that computers can appear at a distance. Instead, this digital framework can open new routes of inquiry toward long-standing problems and recapture some of the magic in computation.

One thought on “Ghost in the Machine”