This post offers a brief reflection on the previous three on distant reading, topic modeling, and natural language processing. These were originally posted to the Digital Humanities at Berkeley blog.
When I began writing a short series of blog posts for the Digital Humanities at Berkeley, the task had appeared straightforward: answer a few simple questions for people who were new to DH and curious. Why do distant reading? Why use popular tools like mallet or NLTK? In particular, I would emphasize how these methods had been implemented in existing research because, frankly, it is really hard to imagine what interpretive problems computers can even remotely begin to address. This was the basic format of the posts, but as I finished the last one, it became clear that the posts themselves were a study in contrasts. Teasing out those differences suggests a general model for distant reading.
Whereas the first post was designed as a general introduction to the field, the latter two had been organized around individual tools. Their motivations were something like: “Topic modeling is popular. The NLTK book offers a good introduction to Python.” More pedagogical than theoretical. However, digging into the research for each tool unexpectedly revealed that the problems NLTK and mallet sought to address were nearly orthogonal. It wasn’t simply that they each addressed different problems, but that they addressed different categories of problems.
Perhaps the place where that categorical difference was thrown into starkest relief was Matt Jockers’s note on part-of-speech tags and topic modeling, which was examined in the post on NLTK. The thrust of his chapter’s argument had been that topic modeling is a useful way to get at literary theme. However, in a telling footnote, Jockers makes the observation that the topics produced from his set of novels looked very different when he restricted the texts to their nouns alone versus including all words. As he found, the noun-only topics seemed to get closer to literary theoretical treatments of theme. This enabled him to proceed answering his research questions, but the methodological point itself was profound: modifying the way he processed his texts into the topic model performed interpretively useful work — even while using the same basic statistical model.
The post on topic modeling itself made this kind of argument implicitly, but along even a third axis. Many of the research projects described there use a similar natural language processing workflow (tokenization, stop word removal) and a similar statistical model (the mallet implementation of LDA or a close relative). The primary difference across them is the corpus under observation. A newspaper corpus makes newspaper topics, a novel corpus makes novel topics, etc. Selecting one’s corpus is then a major interpretive move as well, separate from either natural language processing or statistical modeling.
Of course, in any discussion of topic modeling, the question consistently arises of how even to interpret the topics once they had been produced. What actually is the pattern they identify in the texts? Nearly all projects arrived at a slightly different answer.
I’ll move quickly to the punchline. There seem to be four major interpretive moments that can be found across the board in these distant readings: corpus construction, natural language processing, statistical modeling, and linguistic pattern.
The first three are a formalization of one’s research question, in the sense that they capture aspects of an interpretive problem. For example, returning to the introductory post, Ted Underwood and Jordan Sellers ask the question “How quickly do literary standards change?” which we may recast in a naive fashion: “How well can prestigious vs non-prestigious poetry (corpus) be distinguished over time (model) on the basis of diction (natural language features)?” Answering this formal question produces a measurement of a linguistic pattern. In Underwood and Sellers’s case, this is a list of percentage values representing how likely each text is to be prestigious. That output then requires its own interpretation if any substantial claim is to be made.
(I described my rephrasing of their research question as “naive” in the sense that it had divorced the output from what was interpretively at stake. The authors’ discursive account makes this clear.)
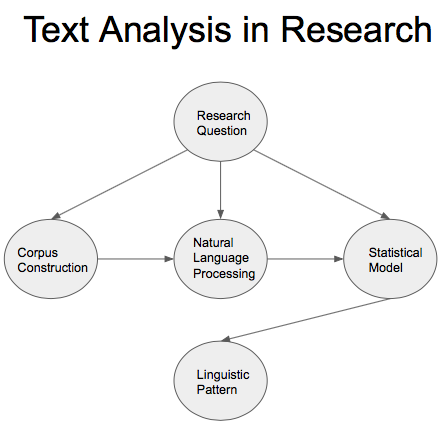
In terms of workflow, all of these interpretive moments occur sequentially, yet are interrelated. The research question directly informs decisions regarding corpus construction, natural language processing, and the statistical model, while each of the three passes into the next. All of these serve to identify a linguistic pattern, which — if the middle three have been well chosen — allows one to answer that initial question. To illustrate this, I offer the above visualization from Laura K. Nelson’s and my recent workshop on distant reading (literature)/text analysis (social science) at the Digital Humanities at Berkeley Summer Institute.
Although these interpretive moments are designed to account for the particular distant readings which I have written about, there is perhaps even a more general version of this model as well. Replace natural language processing with feature representation and linguistic pattern with simply pattern. In this way, we may also account for sound or image based distant readings alongside those of text.
My aim here is to articulate the process of distant reading, but the more important point is that this is necessarily an interpretive process at every step. Which texts one selects to observe, how one transforms the text into something machine-interpretable, what model one uses to account for a phenomenon of interest: These decisions encode our beliefs about the texts. Perhaps we believe that literary production is organized around novelistic themes or cultural capital. Perhaps those beliefs bear out as a pattern across texts. Or perhaps not — which is potentially just as interesting.
Distant reading has never meant a cold machine evacuating life from literature. It is neither a Faustian bargain, nor is it hopelessly naive. It is just one segment in a slightly enlarged hermeneutic circle.
I continue to believe, however, that computers are basically magic.

3 thoughts on “Reading Distant Readings”