The first day of Alan Liu’s Introduction to the Digital Humanities seminar opens with a provocation. At one end of the projection screen is the word DIGITAL and at the other HUMAN. Within the space they circumscribe, we organize and re-organize familiar terms from media studies: media, communication, information, and technology. What happens to these terms when they are modified by DIGITAL or HUMAN? What happens when they modify one another in the presence of those master terms? There are endless iterations of these questions but one effect is clear: the spaces of overlap, contradiction, and possibility that are encoded in the term Digital Humanities.
Pushing off from that exercise, this blog post puts Liu’s question to an extant body of DH scholarship: How does the scholarly discourse of DH organize these media theoretic terms? Indeed, answering that question may shed insight on the fraught relationship between these fields. We can also ask a more fundamental question as well. To what extent does DH discourse differentiate between DIGITAL and HUMAN? Are they the primary framing terms?
Provisional answers to these latter questions could be offered through distant reading of scholarship in the digital humanities. This would give us breadth of scope across time, place, and scholarly commitments. Choosing this approach changes the question we need to ask first: What texts and methods could operationalize the very framework we had employed in the classroom?
For a corpus of texts, this blog post turns to to Matthew K. Gold’s Debates in the Digital Humanities (2012). That edited volume has been an important piece of scholarship precisely because it collected essays from a great number of scholars representing just as many perspectives on what DH is, can do, and would become. Its essays (well… articles, keynote speeches, blog posts, and other genres of text) especially deal with problems that were discussed in the period 2008-2011. These include the big tent, tool/archive, and cultural criticism debates, among others, that continue to play out in 2017.
| Token | Frequency |
| digital | 2729 |
| humanities | 2399 |
| work | 740 |
| new | 691 |
| university | 429 |
| research | 412 |
| media | 373 |
| data | 328 |
| social | 300 |
| dh | 291 |
Table 1. Top 10 Tokens in Matthew K. Gold’s Debates in the Digital Humanities (2012)
The questions we had been asking in class dealt with the relationships among keywords and especially the ways that they contextualize one another. As an operation, we need some method that will look at each word in a text and collect the words that constitute its context. (q from above: How do these words modify one another?) With these mappings of keyword-to-context in hand, we need another method that will identify which are the most important context words overall and which will separate out their spheres of influence. (q from above: How do DIGITAL and HUMAN overlap and contradict one another? Are DIGITAL and HUMAN the most important context words?)
For this brief study, the set of operations ultimately employed were designed to be the shortest line from A to B. In order to map words to their contexts, the method simply iterated through the text, looking at each word in sequence and cumulatively tallying the three words to the right and left of it.1 This produced a square matrix in which each row was a given unique word in Debates and each column represents the number of times that another word had appeared within the given window.2
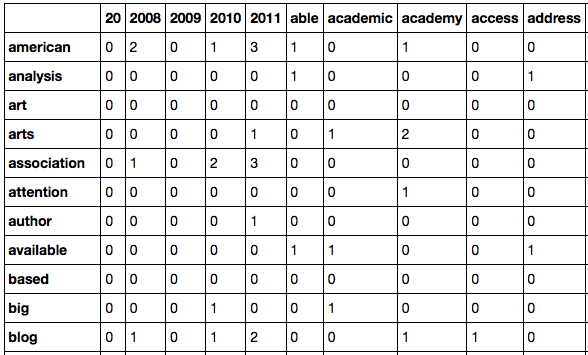
Table 2. Selection from Document-Term Matrix, demonstrating relationship between rows and columns. For example, the context word “2011” appears within a 3-word window of the keyword “association” on three separate occasions in Debates in the Digital Humanities. This likely refers to the 2011 Modern Language Association conference, an annual conference for literature scholars that is attended by many digital humanists.
Principle Component Analysis was then used to identify patterns in that matrix. Without going deeply into the details of PCA, the method looks for variables that tend to covary with one another (related to correlation). In theory, PCA can go through a matrix and identify every distinct covariance (This cluster of context words tends to appear with one another, and this other cluster appears with one another, etc…). In practice, researchers typically only base their analyses on the principle components (in this case, context-word clusters) that account for the largest amounts of variance, since these are the most prominent and least subject to noise.
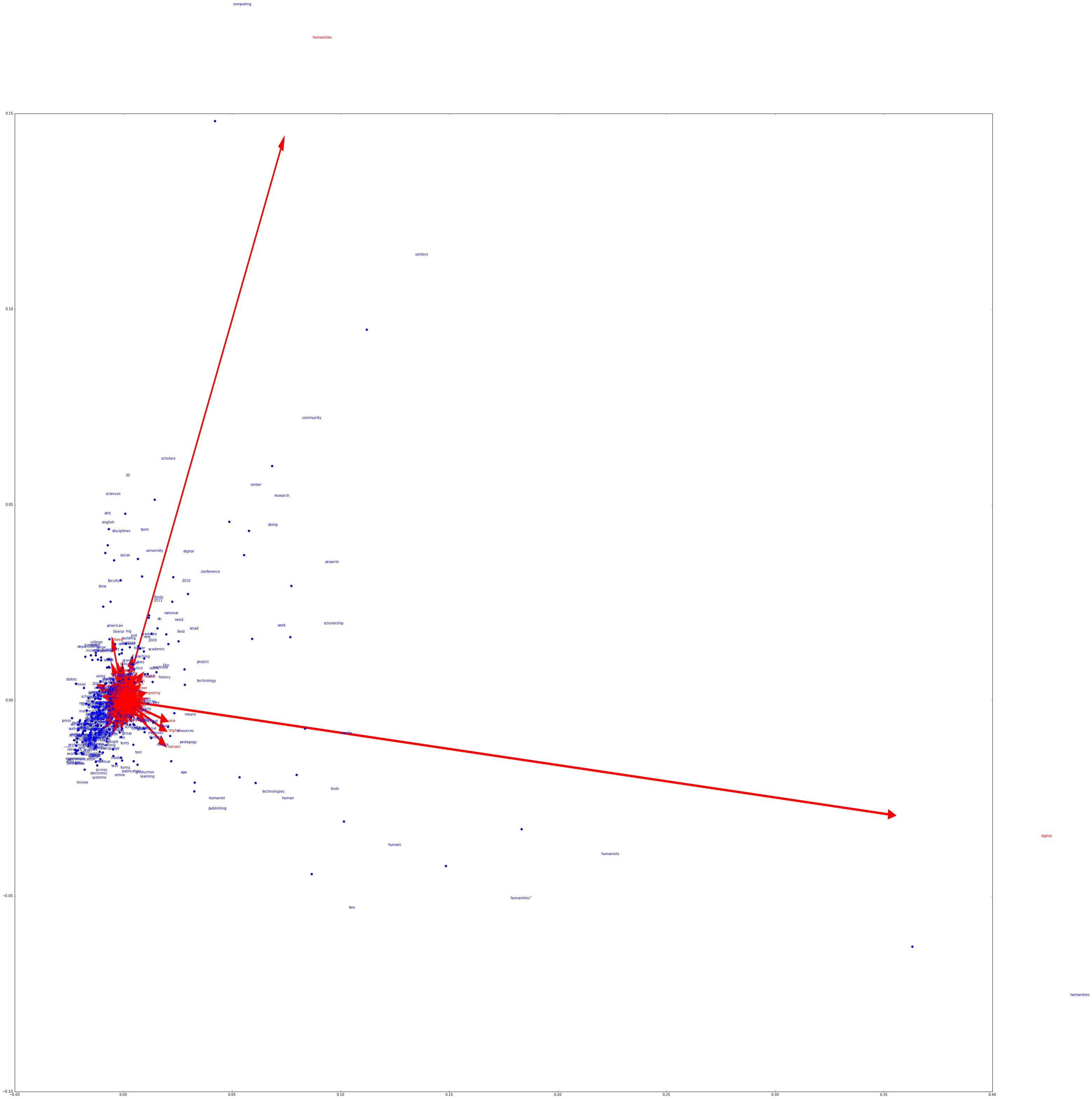
Figure 1. PCA over 300 most frequent keywords and their contexts in Debates in the Digital Humanities. (Click for larger image.)
The above visualization was produced using the first two principle components of the context space and projecting the keywords into it. The red arrows represent the loadings, or important context words, and the blue dots represent the keywords which they contextualize. Blue dots that appear near one another can be thought to have relatively similar contexts in Debates.
What we find is that digital and humanities are by far the two most prominent context words. Moreover, they are nearly perpendicular to one another, which means that they constitute very different kinds of contexts. Alan’s provocation turns out to be entirely well-founded in the literature under this set of operations in the sense that digital and humanities are doing categorically different intellectual work. (Are we surprised that a human close reader and scholar in the field should find the very pattern revealed by distant reading?)
Granted, Alan’s further provocation is to conceive of humanities as its root human, which is not the case in the discourse represented here. This lacuna in the 2012 edition of Debates sets the stage for Kim Gallon’s intervention in the 2016 edition, “Making a Case for the Black Digital Humanities.” That article articulates the human as a goal for digital scholarship under social conditions where raced bodies are denied access to “full human status” (Weheliye, qtd in Gallon). In the earlier edition, then, humanities would seem to be doing a different kind of work.
We can begin to outline the intellectual work that is being done by humanities and digital in 2012 by hanging at this bird’s-eye-view for a few moments longer. There are roughly three segments of context-space as separated by the loading arrows: the area to the upper-left of humanities, that below digital, and the space between these.
The words that are contextualized primarily by humanities describe a set of institutional actors: NEH, arts, sciences, colleges, disciplines, scholars, faculty, departments, as well as that previous institutional configuration “humanities computing.” The words contextualized primarily by digital are especially humanities, humanists, and humanist. (This is after all, the name of the field, they are seeking to articulate.) Further down, however, we find fields of research and methods: media, tools, technologies, pedagogy, publishing, learning, archives, resources.
If humanities had described a set of actors, and digital had described a set of research fields, then the space of their overlap is best accounted by one of its prominent keywords, doing. Other words contextualized by both humanities and digital include: centers, research, community, projects, scholarship. These are the things that we, as digital humanists, do.
Returning to our initial research question, it appears that the media theory terms media and technology are prominently conceived as digital in this discourse, whereas information and communication are not pulled strongly toward either context. This leads us to a new set of questions: What does it mean, within this discourse, for the former terms to be conceived as digital? What lacuna exists that neither of the latter terms is conceived digitally nor humanistically?
The answers to these questions call for a turn to close reading.
Postscript: Debates without the Digital Humanities
During the pre-processing, I made a heavy handed and highly constestable decision. When observing context words, I omitted those appearing in the bi-gram “new york.” That is, I have treated that word pair as noise rather than signal, and the strength of its presence to be a distortion of the scholarly discourse.
The reasoning for such a decision is that it may have been an artifact of method. I have taken a unigram approach to the text, such that the new of “New York” is treated the same as in “new media” or “new forms of research.” At the same time, the quick-and-dirty text ingestion had pulled in footnotes and bibliographies along with the bodies of the essays. This also partly explains why the “new” vector acts as context for dots like “university” and “press” as well. (These words continue to cluster near “new” in Figure 1 but much less visibly or strongly.)

Figure 2. PCA over 300 most frequent keywords and their contexts in Debates in the Digital Humanities, where tokens belonging to the bi-gram “new york” have been included during pre-processing. (Click for larger image.)
If we treat “new york” as textual signal, we may be inclined to draw a few further conclusions. First, as the film cliche goes, “The city is almost another character in the movie.” New York is a synecdoche for an academic institutional configuration that is both experimental and public facing, since the city is its geographic location. Second, the bi-grams “humanities computing” and “digital humanities” are as firmly entrenched in this comparatively new discourse as the largest city in the United States (the nationality of many but not all of the scholars in the volume), which offers a metric for the consistency of their usage.
But we can go in the other direction as well.
As Liu has suggested in his scholarly writing, distant readers may find the practice of “glitching” their texts revealing of institutional and social commitments that animate these. I take one important example of this strategy to be the counterfactual, as has been used by literature scholars in social network analysis. In a sense, this post has given primacy to a glitched/counterfactual version of Debates — from which “new york” has been omitted — and we have begun to recover the text’s conditions of production by moving between versions of the text.
I will close, however, with a final question that results from a further counterfactual. Let’s omit a second bi-gram: “digital humanities.” What do we talk about when we don’t talk about digital humanities?
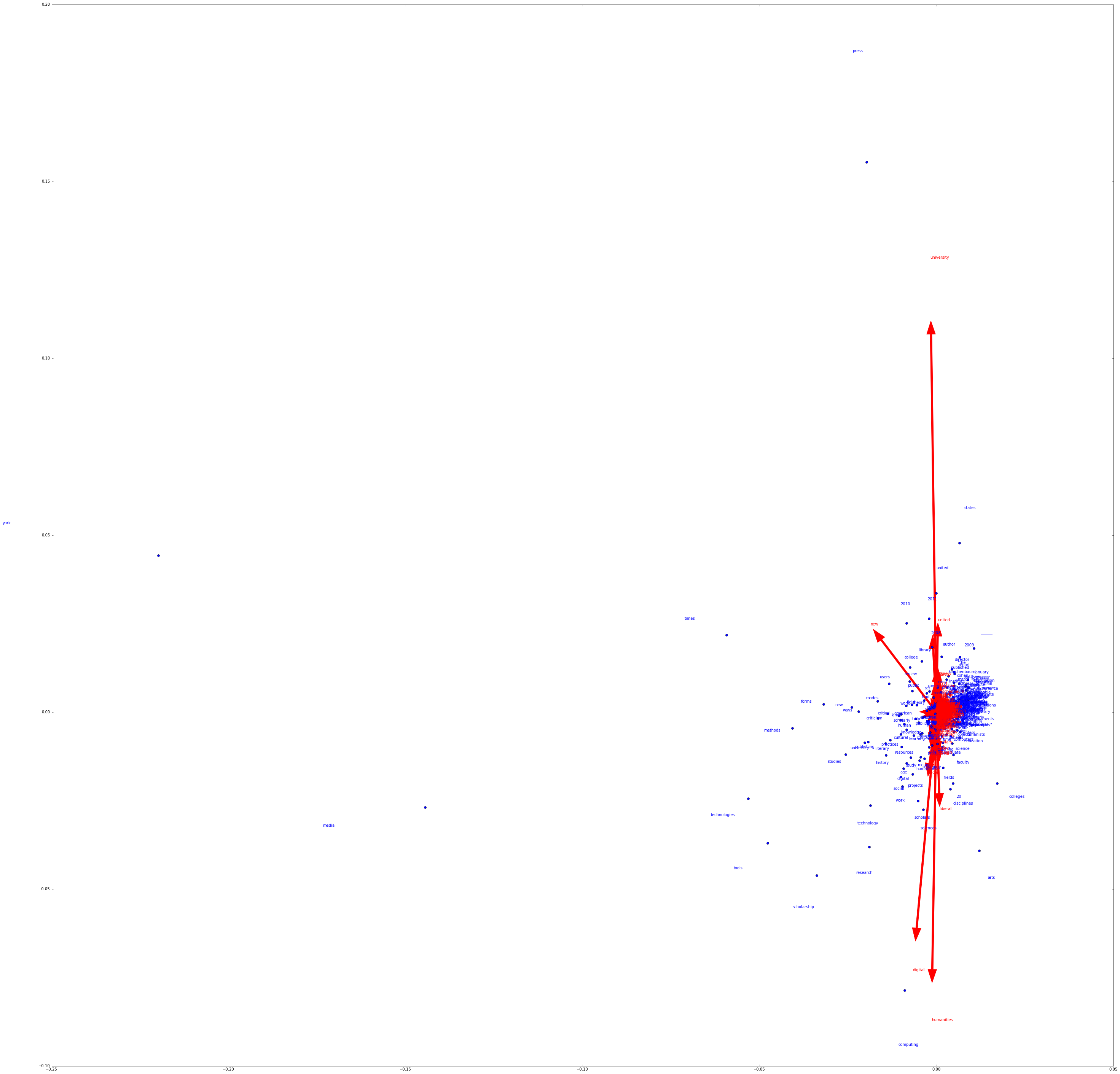
Figure 3. PCA over 300 most frequent keywords and their contexts in Debates in the Digital Humanities, where tokens belonging to the bi-gram “digital humanities” have been excluded during pre-processing. (Click for larger image.)
Footnotes
1. This context-accumulation method is based on one that was developed by Richard So and myself for our forthcoming article “Whiteness: A Computational Literary History.” The interpretive questions in that article primarily deal with semantics and differences in usage, and therefore the keyword-context matrix is passed through a different set of operations than those seen here. However, the basic goal is the same: to observe the relationships between words that are mediated by their actual usage in context.
Note that two parameters must be used in this method: a minimum frequency to include a token as a keyword and a window-size in which context words are observed. In this case, keywords were considered the 300 most common tokens in the text, since our least common keyword of interest “communication” was about the 270th most common token. Similarly, we would hope to observe conjunctions of our media theoretical terms in the presence of either digital or human, so we give these a relatively wide berth with a three-word window on either side.
2. This matrix is then normalized using a Laplace smooth over each row (as opposed to the more typical method of dividing by the row’s sum). In essence, this smoothing asks about the distance of a keyword’s observed context from a distribution where every context word had been equally likely. This minimizes the influence of keywords that appear comparatively few times and increases our confidence that changes to the corpus will not have a great impact on our findings.
This blog post, however, does not transform column values into standard units. Although this is a standard method when passing data into PCA, it would have the effect of rendering each context word equally influential in our model, eliminating information regarding the strength of the contextual relationships we hope to observe. If we were interested in semantics on the other hand, transformation to standard units would work toward that goal.
Update Feb 16, 2017: Code supporting this blog post is available on Github.

3 thoughts on “What We Talk About When We Talk About Digital Humanities”