Author attribution, as a sub-field of stylometry, is well suited to a relatively small set of circumstances: an unsigned letter sent by one of a handful of correspondents, an act of a play written by one of the supposed author’s colleagues, a novel in a series penned by a ghostwriter. The cases where author attribution shines are ones in which there exists (1) a finite list of potential authors (2) for whom we have writing samples in the same genre, and (3) the unknown text is itself long enough to have a clear style. If either of the latter conditions is unmet, the findings start getting fuzzy but are still salvageable. Failing the first condition, all bets are off.
And “Iterating Grace,” fails all three.
When print copies of “IG” — an anonymous short story satirizing tech culture — appeared mysteriously at some very private addresses of San Francisco authors, tech writers, and VCs a couple weeks back, its authorship was almost a challenge posed to its readers. As a journalist at the center of the mystery, Alexis Madrigal, put it,
A work can be detached from its creator. I get that. But keep in mind: the person who wrote this book is either a friend of mine or someone who has kept an incredibly close watch on both a bunch of my friends and the broader startup scene. Books were sent to our homes. Our names were used to aid the distribution of the text.
The conspirators responsible for the book have been alternately playful and reticent regarding their own identities — even as they stole Madrigal’s. And although it appears they plan not to reveal themselves, there has been a great deal of speculation about the author. Clever distribution? Dave Eggers. Intimate knowledge of San Francisco? Robin Sloan. Conspiracy and paranoia? Thomas Pynchon. And these are just the headline names. Some seem more likely, some less.
It is entirely possible that the actual author has not yet been fingered — which we would have no way of knowing — but we could try using some of the established author attribution methods to see if the current suspects will yield any clues about the true author’s style. However, a difficult problem looms over the methods themselves: when we hone in on authors whose style is closer to that of “IG,” how would we even know how close we’ve gotten?
The First Obstacle: Size Matters
The methods I’m using in this blog post — and in a series of graphs tweeted at Madrigal1 — come out of Maciej Eder’s paper “Does size matter? Authorship attribution, short samples, big problem.” (For those who want to follow along at home without too much codework, Eder is a member of the team responsible for the R package stylo, which implements these methods off-the-shelf, and I’m told there’s even a GUI.)2
In the paper, Eder empirically tests a large number of variables among popular attribution methods for their accuracy. He ultimately favors representing the text with a Most Frequent Words vector and running it through a classifier using either the Burrows Delta or a Support Vector Machine algorithm. I used the SVM classifier because, bottom line, there isn’t a good Delta implementation in Python.3 But also, conceptually, using SVM on MFW treats author attribution as a special case of supervised bag-of-words classification, which is a relatively comfortable technique in computational literary analysis at this point. What makes this classifier a special case of bag-of-words is that we want most but not all stopwords. Frequencies of function words like “the,” “of,” and “to” are the authorial fingerprint we’re looking for, but personal pronouns encode too much information about the text from which they are drawn — for instance, whether a novel is first- or third-person. Authorship gets diluted by textual specificity.4
It’s worth a short digression here to think out loud about the non-trivial literary ramification of the assumptions we are making. As Madrigal had said, we often take it as an article of faith that “a work can be detached from its author” but these attribution methods reinscribe authorial presence, albeit as something that hovers outside of and may compete with textual specificity. In particular, pronouns do much of the work marking out the space of characters and objects — if we want to call up Latour, perhaps the super-category of actors — at a level that is abstracted from the act of naming them. In precisely the words through which characters and objects manifest their continuity in a text, the author drops away. Not to mention that we are very consciously searching for features of unique authorship in the space of textual overlap, since words are selected for their frequency across the corpus. The fact that this idea of authorship is present in bag-of-words methods that are already popular suggests that it may be useful to engage these problems in projects beyond attribution.
The “size” referred to in the title of Eder’s paper is that of the writing samples in question. We have a 2000-word5 story that, for the sake of apples-to-apples comparison, we will classify against 2000-word samples of our suspects. But what if the story had been 1000 words or 10,000? How would that change our confidence in this algorithmic classification?
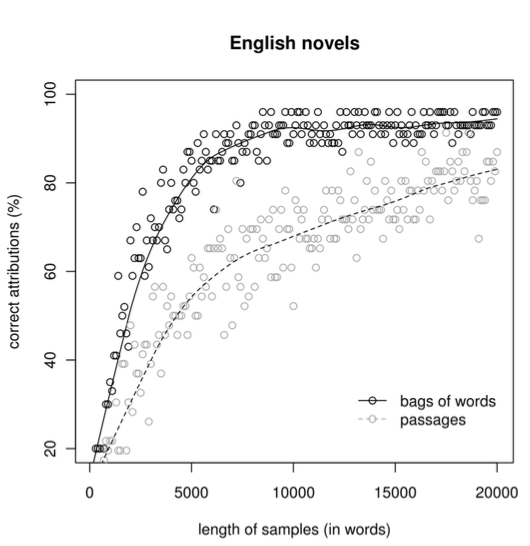
Eder’s Fig. 1: 63 English novels, 200 MFWs (Eder, 4)
Accuracy increases overall as the size of textual samples increases, but there is an elbow around 5000 words where adding words to authors’ writing samples results in diminishing returns. Eder makes a thoughtful note about the nature of this accuracy:
[F]or all the corpora, no matter which method of sampling is used, the rankings are considerably stable: if a given text is correctly recognized using an excerpt of 2,000 words, it will be also ‘guessed’ in most of the remaining iterations; if a text is successfully assigned using 4,000 words, it will be usually attributable above this word limit, and so on. (14)
The classifier accuracy reported on Fig 1’s y-axis is more like the percent of authors for whom their style is recognizable in a bag-of-words of a given size. Also note in the legend that the two different sets of points in the graph represent classification based on randomly selected words (black) vs words drawn from a continuous passage (gray). It comes as a sobering thought that there is at best a 50% chance that “IG” even represents its author’s style, and that chance is probably closer to 30%, since its 2000 words come from a single passage.
I tried to split the difference between those two arcs by using random selections of words from the known suspects’ texts in conjunction with the single passage of “IG.” This is not ideal, so we will need to be up front that we are judging “IG” not against a total accounting of suspects’ style but a representative sample. This situation is begging for a creative solution: one that identifies passages in a novel that are written in a similar mode to the unknown text (e.g. a dialogue, character description, etc) and compare those, but without overfitting or introducing bias into the results. Sure, Eggers’ dialogue won’t look like “IG” — because the story has no dialogue — but what about the moments when he reports a character’s backstory? My hasty solution was simply to take many random selections of words from suspects’ much larger works since, in aggregate, they will account for the texts’ normative degrees of variation; authors are spread out over stylistic space, weighted by their different modes of writing. In the event that “IG” is largely unrepresentative of its author’s style, it may still fall within their stylistic field near similar slices of text, if only at the periphery.
Intertwined Obstacles: Unusual Suspects
Now that the table has been set, let’s take a look at some of the names that have been thrown around. (For convenience, I will also list their most recent work, where it was included in the corpus.)
- Caroline Paul — Lost Cat
- Joshua Cohen — Book of Numbers
- Po Bronson — assorted fiction6
- Mat Honan — WIRED narrative non-fiction
- Paul Ford — “What is Code?“
- Tim Leong
- Alexis Madrigal
- Curtis Schreier
Each of these suspects was named by Madrigal, including admittedly himself. But I’d like to point out that many of these names are not fiction writers: Schreier is a performance artist, most known for his work in the 70s; Leong has primarily published infographics recently; Ford, Madrigal, and Honan are all journalists. That is, we have a suspect for whom we have no known published material and four journalists who write on sliding scale of narrativity. (One other suspect I looked into had published almost exclusively Buzzfeed listicles.) Honan and Ford have both published long-form pieces recently, and those have been included in the corpus, but the others’ absence must be noted.
Other names that have come up more than once include:
- Robin Sloan — Mr. Penumbra’s 24-hour Bookstore
- Dave Eggers — The Circle
- Thomas Pynchon — Bleeding Edge
- Susan Orlean — New Yorker narrative non-fiction, The Orchid Thief
- the horse_ebooks/Pronunciation Book guys
In evaluating the list of suspects, the nature of detective work encroaches on the role of the literary historian. Sure, those two always overlap, but our cases are usually a century or two cold. To put a very fine point on it, I actually staked out a cafe in San Francisco and met Schreier last week, so that I could ask him, among other things, whether he had published any writing during his career. He had not. But the sleuthing has a degree of frankness that we pretend to disavow as historians. (Do we really think Thomas Pynchon, a hulking literary giant of our time, organized this essentially provincial gag? Maybe I’m wrong. Just a hunch.) To wit, we have to remain skeptical of Madrigal’s reportage, since it may all be a ruse. We may be his dupes, complicit in his misdirection. As he put it to another journalist on the case, Dan Raile, “Of course the most obvious answer would be that it is me and Mat Honan.” Even the assumption that there is a list of suspects beyond Madrigal (and Honan) remains provisional. But it’s the best we’ve got.
At a more practical level, the uneven coverage of our most likely suspects points out the complexity of what is referred to as author attribution “in the wild.” The assumption that the true author is already a member of the list of suspects — called the closed-world assumption — has come under scrutiny recently in stylometry.7 This partly kicks the question of attribution over to verification, a measure of confidence in any given attribution. But the case of “IG” intersects with other open problems of corpus size, as well as cross-genre attribution that makes some of the proposed open-world solutions difficult to apply. Knowing this, and with our eyes wide open, let’s see just how far the closed-world methods can take us.
Interpreting Attribution
Using the version of supervised learning that Eder had recommended (SVM classifier, MFW vector minus personal pronouns), I ran it over the corpus of suspects. Each suspect’s text was represented by 100 different bags of 2000 randomly selected words. Under cross-validation, the classifier easily had 100% accuracy among the suspects. Once the classifier had been trained on these, it was shown “IG” in order to predict its author.
I’ll cut to the chase: if the author is already in our list of suspects, the classifier is confident that she is Susan Orlean, based on the style her recent work in the New Yorker. Under one hundred iterations of four-fold cross-validation — in which three fourths of suspects’ texts were randomly chosen for training in each iteration rather than the entire set — the classifier selected Orlean as the author of “IG” 100% of the time. I also tried replacing her New Yorker pieces with The Orchid Thief, since it is a longer, unified text, to the same result. (When including both in the corpus simultaneously, the classifier leaned toward the New Yorker, with about a 90%-10% split.8) The fact that this kind of cross-validated prediction is proposed as one kind of verification method — albeit one that is more robust with a longer list of suspects — indicates that something important might be happening stylistically in Orlean. In order to explore what some of those features are, there are a few methods closely related to Eder’s that we can use to visualize stylistic relationships.
Two popular unsupervised methods include visualizing texts’ MFW vectors using Cosine Similarity and Principle Component Analysis (PCA), projected into 2-D space. These appear in Fig 2. (Note that Orlean is represented only by her recent New Yorker work.) In these graphs, each of the Xs represents a 2000-word slice of its text. I won’t go into detail here about Cosine Similarity and PCA as methods, except to say that Cosine Similarity simply measures the overlap between texts on a feature-by-feature basis and PCA attempts to find features that do the most to distinguish among groups of texts. In both graphs, the distance between Xs approximates their similarity on the basis of the different measurements used. Overlaid on the PCA graph are the top loadings — words that help distinguish among groups, along with the direction and magnitude of their influence on the graph.
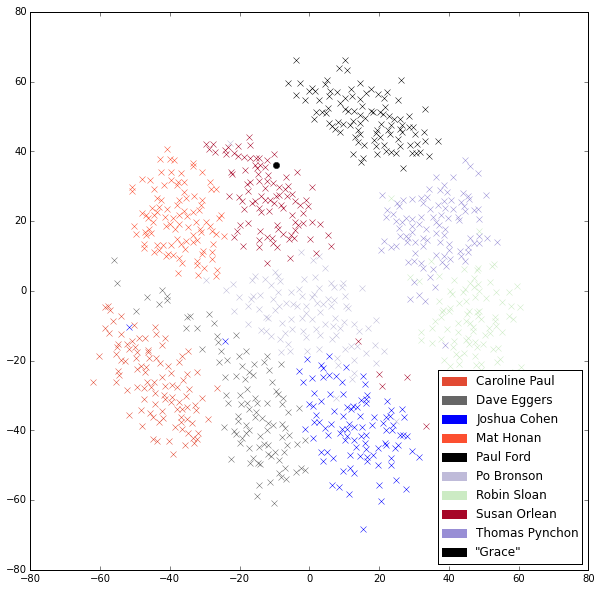
Fig 2a. Cosine Similarity over suspects’ MFW vectors
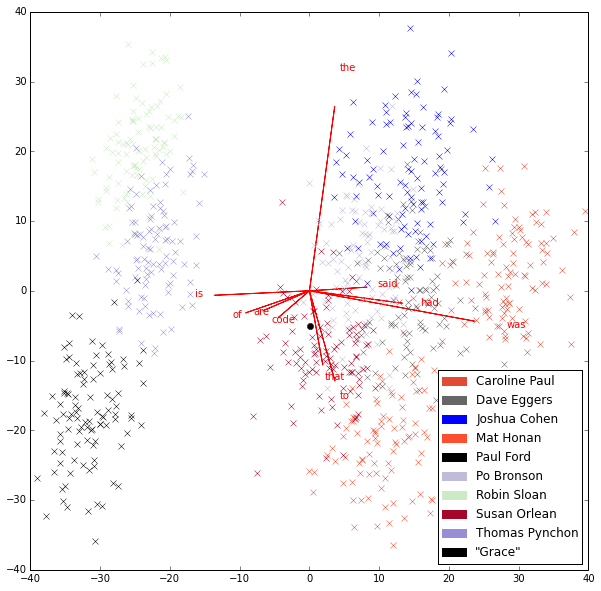
Fig 2b. PCA over suspects’ MFW vectors, with top 10 loadings
The most striking feature of these graphs — beyond the fact that IG resides well within the spaces circumscribed by Orlean’s style — is the gulf between most of the writers and a group of three: Robin Sloan, Thomas Pynchon, and Paul Ford. I had been unsure about what to make of their grouping, until I looked at the loadings prominent in the first principle component (on the x-axis) in Fig 2b. Is and are stretch out to the left, indicating those are prominent words shared among the three, and those loadings are diametrically opposed to said, had, and was. The gulf appears to be an issue of present tense versus past and glancing over those texts confirms this to be the case. There is, however, one loading that troubles the easiness of verb tense as our explanation: of. It appears to be strongly tied to verbs in the present tense, although it does a very different kind of conceptual work.
Attribution methods purport to measure something about an authorial fingerprint, but the question of what precisely gets measured remains unsettled. The MFW vector doesn’t quite capture grammar but neither does it reduce to word choice. Counting how often an author uses “the” tells us something about how often nouns show up, how they relate to one another, whether nouns tend to be abstract or concrete, unique or one of a set. Many such high-level concepts intersect on each of the high-frequency words we count. It would be impossible to account entirely for the way(s) in which an author orients the reader to the content of the text based on a single such word frequency, but hundreds of them might. This partly sounds like a Jacobsonian problem in which we try to learn parameters for the axes of selection and combination, but I think our goals are closer to those of generative grammar: What are the habits of the author’s cognition? How does the text think its content? And how do we interpret that thinking through these most frequent words?
The findings in Fig 2 are far too provisional to determine whether of is a universally important feature to present tense constructions, but the idea that it is important to Ford, Pynchon, and Sloan’s constructions of the present is certainly compelling.
The phenomenon captured by the second principle component (the y-axis in Fig 2b.) is less obvious at first glance, but looking back over the texts included for the corpus, there is a clear division between fiction and non-fiction. Xs belonging to Ford, Honan, and Orlean tend to have more negative values. It is well known that author attribution methods are sensitive to genre, even among writings by the same author, so it is satisfying to have found that difference among texts without having made it an a priori assumption. In light of this, however, the loadings are all the more curious: the is a very strong indicator of fiction, whereas that and to construct the conceptual landscape of non-fiction reportage. Does this conform to our understanding of non-fiction as characterized by specification or causation? Or of fiction by the image?
The other work of non-fiction, Lost Cat by Caroline Paul, hovers around zero on the y-axis, but the text opens with a suddenly prescient note:
This is a true story. We didn’t record the precise dialogue and exact order of events at the time, but we have re-created this period of our lives to the best of our mortal ability. Please take into account, however: (1) painkillers, (2) elapsed time, (3) normal confusion for people our age.
Paul’s humorous memoir about a traumatic, confusing period (involving a major injury, hence the painkillers) straddles the line we’ve found between long-form reportage and fictitious-world building. Maybe this is exactly what we mean by the conjunction inherent to narrative non-fiction.
The style of “IG,” then, leans slightly toward non-fiction. That’s not entirely surprising, since the story is framed as a book’s preface. The fictitious book Iterating Grace is supposed to have been written (or rather compiled from Twitter) by Koons Crooks — an out-of-work programmer cum spiritualist. The “short story” we have examined is Iterating Grace‘s anonymous introduction describing what little we know about Crooks’ biography. Action is reported after-the-fact rather than ongoing; the story is centered on a single protagonist whom we don’t see interacting much with other characters; the narrator reflects periodically, trying to understand the motivations of the protagonist. This sounds like a New Yorker article. And if we interpret “IG” to lie within Orlean’s stylistic field in the PCA graph, it lies among the slices of her articles that lean toward fiction.
Despite these similarities in features of generic importance, the fact that IG lies on the edge of her field in the scaled Cosine Similarity graph qualifies the strength of the PCA finding. Without going into the multidimensional scaling formula, IG may be artificially close to Orleans’ work in the Cosine Similarity graph simply because hers is the least dissimilar. This is precisely the kind of uncertainty that verification hopes to resolve. I will, however, sidestep the largest question of whether Orlean is the author of “IG,” in order to ask one about her style. Since we have established that “IG” is similar to Orlean’s non-fiction at its most fictional, I want to know how similar. What degree of resemblance does “IG” bear to the normative range of her work?
To answer this question, I propose not a sophisticated verification method, but a naive one: the smell test.
Naive Attribution: The Smell Test
One of the limitations of using MDS over many different authors, as in Fig 2a, is that it has to negotiate all of their relationships to one another, in addition to their degree of internal differentiation. Therefore, I would suggest that we simply observe the scaled Cosine graphs for each author individually to a single dimension and, then, locate “IG” on it. This has the virtue of capturing information about the normative co-occurance of features in the author’s stylistic field and using that to gauge the textual features of “IG.”
For the sake of comparison, I will show, along with Orlean, the authors who are the next most similar to and the most different from “IG” by this method, Po Bronson and Robin Sloan respectively.

Fig 3a. Stylistic variation in Susan Orlean’s New Yorker non-fiction over 2000-word slices

Fig 3b. Stylistic variation in Po Bronson’s fiction over 2000-word slices

Fig 3c. Stylistic variation in Robin Sloan’s Mr. Penumbra over 2000-word slices
Taking the author’s style as a field circumscribed by so many slices of their text, “IG” lies fully outside of our visualization of that field for both Bronson and Sloan, and just within the periphery for Orlean. Another way to put it is that most of the slices of Orlean’s style are on average more similar to “IG” than they are to her most dissimilar slice. This is certainly not a resounding endorsement for her authorship of “IG,” but it helps us to understand where “IG” falls within her field. The story is just at the outer limit of what we would expect to see from her under normal circumstances. Should she reveal herself to be the true author of “IG” at some point in the future, we would know that it had been a stylistic stretch or an experiment for her. Should either Bronson or Sloan do the same, then we might be compelled to interpret IG as a stylistic break.
I would like to emphasize, however, that the smell test is just that: a non-rigorous test to evaluate our hunches. (Perhaps we can start to imagine a more rigorous version of it based not on MDS but on taking each slice’s median similarity to the others.) I do not want to overstate its value as a verification method, but instead guide our attention toward the idea of an expected degree of stylistic variation within a text and the question of how we account for that, especially in our distant reading practices. The decision to include stopwords (or not) is already understood to be non-trivial, but here we can see that their variations within the text are potentially interpretable for us. One of the risks of modeling an entire novel as a single bag of words is that it may be rendered artificially stable viz the relative frequencies of words and the conceptual frameworks they convey.
Reiterating Grace
So what do we make of the idea that Susan Orlean might be the author of “Iterating Grace?” Her name was probably the most out of place on our initial list of suspects (along with Pynchon, in my opinion). But with the door open on Orlean’s potential authorship, I’d direct attention to Steve DeLong’s hypothesis that she penned it, so it could be distributed by Jacob Bakkila and Thomas Bender, the masterminds behind horse_ebooks and Pronunciation Book. For the uninitiated, these were internet performance art pieces that involved Tweeting and speaking aloud borderline intelligible or unexpected phrases. One of the Internet’s longer-running mysteries was whether horse_ebooks had been run by a human or a poorly-coded Twitterbot. If you would like to know more about Bakkila and Bender, perhaps Orlean’s profile for the New Yorker would interest you.
I’ll refrain from speculative literary history, but DeLong’s approach should remind us to look outside the text for our theorization of its authorship, even as we dig in with computational tools. If we understand a text’s most frequent words to convey something about its conceptual geography, then we might reframe the story as a kind of problem posed to Orlean by Bakkila and Bender, or that it lies at the intersection of problems they work on in their writing and performance art respectively. This suggests that evidence of a potential collaboration may be visible in the text itself. Unfortunately for our methods, even if we wanted to suss out the intellectual contributions of those three maybe-conspirators, most of Bakkila’s published material is the almost-but-never-quite gibberish of horse_ebooks. This returns us to the fundamental problem of attribution in the wild.
In case I have overstated the likelihood of Orlean’s authorship, I offer this qualification. I reran this experiment with one parameter changed. Instead of randomly sampling words from suspects’ texts for the MFW vector, I selected continuous passages, as represented by the lower arc in Eder’s Fig 1. In fact, the overall results were very similar to the ones I have discussed but fuzzier. For instance, even though nine of the top ten loadings from the PCA were the same, the boundaries between author-spaces were less well-defined in that graph, as well as among their Cosine Similarities.
Bottom line, the SVM classifier still typically attributed authorship to Orlean, but depending on the particular passages and training set also often chose Joshua Cohen, whose new novel, Book of Numbers, was published suspiciously close to the first appearance of “IG.” And every now and then, when passages lined up just right, the classifier chose Thomas Pynchon or Po Bronson. (Although it was mostly consistent with the SVM predictions, the smell test was similarly sensitive to the selected passages.) In passages of 2000 words, authorial style is far less differentiable than under samples of the same size: word frequencies reduce quickly to artifacts of their passages. I don’t say this to invalidate the findings I’ve shared at all. Comparing “IG” to the random samples of other authors gave us stylistic points of reference at a high resolution. Instead I hope to make clear that when we try to determine its authorship, we need to decide whether we interpret “IG” as something representative or artifactual. Is the text an avatar for an author we probably will never know or is it simply the product of strange circumstances?
That is perhaps the most important question to ask of a story that begins:
You don’t need to know my name. What’s important is that I recently got a phone call from a young man outside Florence named Luca Albanese. (That’s not his name either.) … He’d had an extraordinary experience, he said, and was in possession of “some unusual materials” that he thought I should see.
Framed by its own disavowel of authorship and identity, “Iterating Grace” is a set of unusual materials — not quite a story — asking only that we bear witness.
1Also tweeting graphs at Madrigal was Anouk Lang, who very generously corresponded with me about methods and corpora. Any intuition that I have gained about stylometric methods has to be credited to her. And reflecting on digital collaboration for a moment, Anouk’s reaching out initially via tweet and the back-and-forth that followed demonstrates for me the power of Twitter as a platform, should we all be so generous.
2Hat tip to Camille Villa for passing along Eder’s work. The DHSI 2015 organizers can rest easy knowing that workshop knowledge is being shared widely.
3The Burrows’s Delta has enjoyed popularity among stylometrists but is somewhat provincial to that field. It is essentially a distance measure between vectors, like Cosine Similarity, but that normalizes feature distances based on their standard deviation across the corpus. See Argamon, “Interpreting Burrows’s Delta: Geometric and Probabilistic Foundations”
4David Hoover recommends further minimizing textual specificity — relative to other texts in the corpus as well as to the author’s personal style — by including in the MFW vector only those words that appear in at least 60-80% of all texts in the corpus, as a rule of thumb. This is one major parameter that Eder does not explore systematically, suggesting that he may not use a minimum document frequency. In his test of different MFW vector sizes, Eder confirms Hoover’s general recommendation that larger MFW vectors perform better (up to about 15,000 words), but adds the qualification that optimal vector size will vary with writing sample size. Since IG is 2000 words and my corpus is relatively small, I will use a 500-word vector without a minimum document frequency.
5Madrigal puts the word count at 2001 — which feels symbolic for a story about the end of the dot-com bubble — although my (imperfect) tokenizer lands at 1970. For convenience, I have referred throughout the blog post to sets of 2000 words, but in practice, I have used 1970 tokens.
6Eder validates the practice of stitching together multiple pieces in the same genre by an author, and I have done this with Bronson, Honan, and Orlean.
7Stolerman, et al. “Classify, but Verify: Breaking the Closed-World Assumption in Stylometric Authorship Attribution.” The Tenth Annual IFIP WG 11.9 International Conference on Digital Forensics. January 2014. Vienna, Austria.; Koppel et al. “The Fundamental Problem of Authorship Attribution.” English Studies. 93.3 (2012): 284-291.
8Readers who follow the link to Steve DeLong’s blog post that is embedded toward the end of this one, will find there an excerpt of an email I had sent him with some of my findings. In that email I had reported the opposite effect: when the classifier examined both Orlean’s New Yorker pieces and The Orchid Thief, it leaned toward the latter. At the time, I had been experimenting with different parameters and had followed Hoover’s suggestion to include only words with a minimum document frequency of 60%. In fact, this had reduced the size of the MFW vector to under 200. Since then, I have preferred to not to use a minimum document frequency and simply to use the 500 most frequent words, due to the smallness of the corpus.
