This post originally appeared on the Digital Humanities at Berkeley blog. It is the second in what became an informal series. Images have been included in the body of this post, which we were unable to originally. For a brief reflection on the development of that project, see the more recent post, Reading Distant Readings.
Computer reading can feel like a Faustian bargain. Sure, we can learn about linguistic patterns in literary texts, but it comes at the expense of their richness. At bottom, the computer simply doesn’t know what or how words mean. Instead, it merely recognizes strings of characters and tallies them. Statistical models then try to identify relationships among the tallies. How could this begin to capture anything like irony or affect or subjectivity that we take as our entry point to interpretive study?
I have framed computer reading in this way before – simple counting and statistics – however I should apologize for misleading anyone, since that account gives the computer far too much credit. It might imply that the computer has an easy way to recognize useful strings of characters. (Or to know which statistical models to use for pattern-finding!) Let me be clear: the computer does not even know what constitutes a word or any linguistically meaningful element without direct instruction from a human programmer.
In a sense, this exacerbates the problem the computer had initially posed. The signifier is not merely divorced from the signified but it is not even understood to signify at all. The presence of an aesthetic, interpretable object is entirely unknown to the computer.
Teasing out the depth of the computer’s naivety to language, however, highlights the opportunity for humanists to use computers in research. Simply put, the computer needs a human to tell it what language consists of – that is, which objects to count. Following the description I’ve given so far, one might be inclined to start by telling the computer how to find the boundaries between words and treat those as individual units. On the other hand, any humanist can tell you that equal attention to each word as a separable unit is not the only way to traverse the language of a text.
Generating instructions for how a computer should read requires us to make many decisions about how language should be handled. Some decisions are intuitive, others arbitrary; some have unexpected consequences. Within the messiness of computer reading, we find ourselves encoding an interpretation. What do we take to be the salient features of language in the text? For that matter, how do we generally guide our attention across language when we perform humanistic research?
The instructions we give the computer are part of a field referred to as natural language processing, or NLP. In the parlance, natural languages are ones spoken by humans, as opposed to the formal languages of computers. Most broadly, NLP might be thought of as the translation from one language type to another. In practice, it consists of a set of techniques and conventions that linguists, computer scientists, and now humanists use in the service of that translation.
For the remainder of this blog post, I will offer an introduction to the Natural Language Toolkit, which is a suite of NLP tools available for the programming language Python. Each section will focus on a particular tool or resource in NLTK and connect it to an interpretive research question. The implicit understanding is that NLP is not a set of tools that exists in isolation but necessarily perform part of the work of textual interpretation.
I am highlighting NLTK for several reasons, not the least of which is the free, online textbook describing their implementation (with exercises for practice!). That textbook doubles as a general introduction to Python and assumes no prior knowledge of programming.[1] Beyond pedagogical motivation, however, NLTK contains both tools that are implemented in a great number of digital humanistic projects and others that have not yet been fully explored for their interpretive power.
from nltk import word_tokenize
As described above, the basic entry point into NLP is simply to take a text and split it into a series of words, or tokens. In fact, this can be a tricky task. Even though most words are divided by spaces or line breaks there are many exceptions, especially involving punctuation. Fortunately, NLTK’s tokenizing function, word_tokenize(), is relatively clever about finding word boundaries. One simply places a text of interest inside the parentheses and the function returns an ordered list of the words it had contained.
As it turns out, simply knowing which words appear in a text encodes a great deal of information about higher-order textual features, such as genre. The technique of dividing a text into tokens is so common it would be difficult to offer a representative example, but one might look at Hoyt Long and Richard So’s study of the haiku in modernist poetry, “Literary Pattern Recognition: Modernism between Close Reading and Machine Learning.” They use computational methods to learn the genre’s distinctive vocabulary and think about its dissemination across the literary field.

“A sample list of probability measures generated from a single classification test. In this instance, the word sky was 5.7 times more likely to be associated with nonhaiku (not-haiku) than with haiku. Conversely, the word snow was 3.7 times more likely to be associated with haiku than with nonhaiku (not-haiku).” Long, So 236; Figure 8
I would point out here that tokenization itself requires interpretive decisions be made on the part of the programmer. For example, by default when word_tokenize() sees the word “wouldn’t” in a text, it will produce two separate tokens “would” and “n’t”. If one’s research question were to examine ideas of negation in a text, it might serve one well to tokenize in this way, since it would handle all negative contractions as instances of the same phenomenon. That is, “n’t” would be drawn from “shouldn’t” and “hadn’t” as well. On the other hand, these default interpretive assumptions might adversely affect your research into a corpus, so NLTK offers the capability to turn that aspect of its tokenizer off.
NLTK similarly offers a sent_tokenize() function, if one wishes to divide the text along sentence boundaries. Segmentation at this level underpins the stylistic study by Sarah Allison et al in their pamphlet, “Style at the Scale of the Sentence.”
from nltk.stem import *
When tokens consist of individual words, they contain a semantic meaning but in most natural languages they carry grammatical inflection as well. For example, love, loves, lovable, and lovely all have the same root word while the ending maps it into a grammatical position. If we wish to shed grammar in order to focus on semantics, there are two major strategies.
The simpler and more flexible method is to artificially re-construct a root word – the word’s stem – by removing common endings. A very popular function that gets used for this is the SnowballStemmer(). For example, all of the words listed above are stemmed to lov. The stem itself is not a complete word but captures instances of all forms. Snowball is especially powerful in that it is designed to work for many Western languages.
If we wish to keep our output in the natural language at hand, we may prefer a more sophisticated but less universally applicable technique that identifies a word’s lemma, essentially its dictionary form. For English nouns, that typically means changing plurals to singular; for verbs it means the infinitive. In NLTK, this is done with WordNetLemmatizer(). Unless told otherwise, that function assumes all words are nouns, and as of now, it is limited to English. (This is just one application of WordNet itself, which I will describe in greater detail below.)
As it happens, Long and So performed lemmatization of nouns during the pre-processing in their study above. The research questions they were asking revolved around vocabulary and imagery, so it proved expedient to collapse, for instance, skies and sky into the same form.
from nltk import pos_tag
As trained readers, we know that language partly operates according to (or sometimes against!) abstract, underlying structures. For as many cases where we may wish to remove grammatical information from our text by lemmatizing, we can imagine others for which it is essential. Identifying a word’s part of speech, or tagging it, is an extremely sophisticated task that remains an open problem in the NLP world. At this point, state-of-the-art taggers have somewhere in the neighborhood of 98% accuracy. (Be warned that accuracy is typically gauged on non-literary texts.)
NLTK’s default tagger, pos_tag(), has an accuracy just shy of that with the trade-off that it is comparatively fast. Simply place a list of tokens between its parentheses and it returns a new list where each item is the original word alongside its predicted part of speech.
This kind of tool might be used in conjunction with general tokenization. For example, Matt Jockers’s exploration of theme in Macroanalysis relied on word tokens but specifically those the computer had identified as nouns. Doing so, he is sensitive to the interpretive problems this selection raises. Dropping adjectives from his analysis, he reports, loses information about sentiment. “I must offer the caveat […] that the noun-based approach used here is specific to the type of thematic results I wish to derive; I do not suggest this as a blanket approach” (131-133). Part-of-speech tags are used consciously to direct the computer’s attention toward features of the text that are salient to Jockers’ particular research question.

Thematically related nouns on the subject of “Crime and Justice;”
from Jockers’s blog post on methods
Recently, researchers at Stanford’s Literary Lab have used the part-of-speech tags themselves as objects for measurement, since they offer a strategy to abstract from the particulars of a given text while capturing something about the mode of its writing. In the pamphlet “Canon/Archive: Large-scale Dynamics in the Literary Field,” Mark Algee-Hewitt counts part-of-speech-tag pairs to think about different “categories” of stylistic repetition (7-8). As it happens, canonic literary texts have a preference for repetitions that include function words like conjunctions and prepositions, whereas ones from a broader, non-canonic archive lean heavily on proper nouns.
from nltk import ne_chunk
Among parts of speech, names and proper nouns are of particular significance, since they are the more-or-less unique keywords that identify phenomena of social relevance (including people, places, and institutions). After all, there is just one World War II, and in a novel, a name like Mr. Darcy typically acts as a more-or-less stable referent over the course of the text. (Or perhaps we are interested in thinking about the degree of stability with which it is used!)
The identification of these kinds of names is referred to as Named Entity Recognition, or NER. The challenge is twofold. First, it has to be determined whether a name spans multiple tokens. (These multi-token grammatical units are referred to as chunks; the process, chunking.) Second, we would ideally distinguish among categories of entity. Is Mr. Darcy a geographic location? Just who is this World War II I hear so much about?
To this end, the function ne_chunk() receives a list of tokens including their parts of speech and returns a nested list where named entities’ tokens are chunked together, along with their category as predicted by the computer.
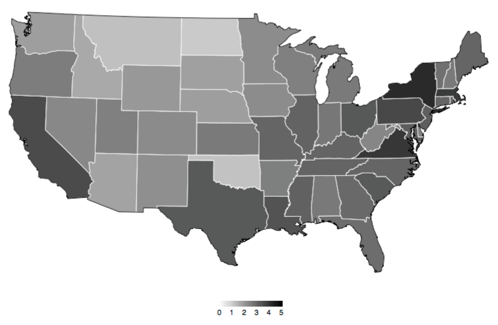
Log-Scaled Counts of named locations by US State, 1851-1875; Wilkens 6, Figure 4
Similar to the way Jockers had used part of speech to instruct the computer which tokens to count, Matt Wilkens uses NER to direct his study of the “Geographic Imagination of Civil War Era American Fiction.” By simply counting the number of times each unique location was mentioned across many text (and alternately the number of novels in which it appeared), Wilkens is able to raise questions about the conventional wisdom around the American Renaissance, post-war regionalism, and just how much of a shift in literary attention the war had actually caused. Only chunks of tokens tagged GPE, or Geo-Political Entity, are needed for such a project.
from nltk.corpus import wordnet
I have spent a good deal of time explaining that the computer definitionally does not know what words mean, however there are strategies by which we can begin to recover semantics. Once we have tokenized a text, for instance, we might look up those tokens in a dictionary or thesaurus. The latter is potentially of great value, since it creates clusters among words on the basis of meaning (i.e. synonyms). What happens when we start to think about semantics as a network?
WordNet is a resource that organizes language in precisely this way. In its nomenclature, clusters of synonyms around particular meanings are referred to as synsets. WordNet’s power comes from the fact that synsets are arranged hierarchically into hypernyms and hyponyms. Essentially, a synset’s hypernym is a category to which it belongs and its hyponyms are specific instances. Hypernyms for “dog” include “canine” and “domestic animal;” the hyponyms include “poodle” and “dalmatian.”
This kind of “is-a” hierarchical relationship goes all the way up and down a tree of relationships. If one goes directly up the tree, the hypernyms become increasingly abstract until one gets to a root hypernym. These are words like “entity” and “place.” Very abstract.
As an interpretive instrument, one can broadly gauge the abstractness – or rather, the specificity – of a given word by counting the number of steps taken to get from the word to its root hypernym, i.e. the length of the hypernym path. The greater the number of steps, the more specific the word is thought to be. In this case, the computer ultimately reads a number (a word’s specificity score) rather than the token itself.
In her study of feminist movements across cities and over time, “Political Logics as Cultural Memory: Local Continuities and Women’s Organizations in Chicago and New York City”, Laura K. Nelson gauges the abstractness of each movement’s essays and manifestos by measuring the average hypernym path length for each word in a given document. In turn, she finds that movements out of Chicago had tended to focus on specific events and political institutions whereas those out of New York situate themselves among broader ideas and concepts.
from nltk.corpus import cmudict
Below semantics, below even the word, is of course phonology. Phonemes lie at a rich intersection of dialect, etymology, and poetics that digital humanists have only just begun to explore. Fortunately, the process of looking up dictionary pronunciations can be automated using a resource like the CMU (Carnegie Mellon University) Pronouncing Dictionary.
In NLTK, this English-language dictionary is distributed as a simple list in which each entry consists of a word and its most common North American pronunciations. The entry includes not only the word’s phonemes but whether syllables are stressed or unstressed. Texts then are no longer processed into semantically identifiable units but into representations of its aurality.
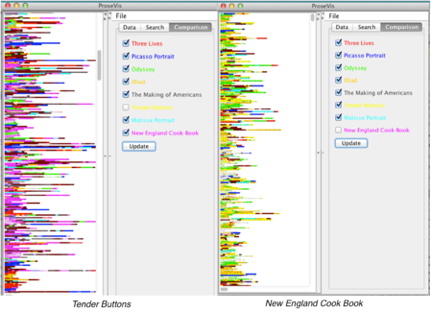
Segments of each text colored by their aural affinities to each of the other books under consideration. For example, the window on the left shows the text of Tender Buttons, while the prevalence of fuchsia highlighting indicates its aural similarity to the New England Cook Book; Clement et al, Figure 14
These features, among others, form the basis of a study by Tanya Clement et al on aurality in literature, “Sounding for Meaning: Using Theories of Knowledge Representation to Analyze Aural Patterns in Texts”.[2] In the essay, the authors computationally explore the aural affinity between the New England Cookbook and Stein’s poem “Cooking” in Tender Buttons. Their findings offer a tentative confirmation of Margueritte S. Murphy‘s previous literary-interpretive claims that Stein “exploits the vocabulary, syntax, rhythms, and cadences of conventional women’s prose and talk” to “[explain] her own idiosyncratic domestic arrangement by using and displacing the authoritative discourse of the conventional woman’s world.”
Closing Thought
Looking closely at NLP – the first step in the computer reading process – we find that our own interpretive assumptions are everywhere present. Our definition of literary theme may compel us to perform part-of-speech tagging; our theorization of gender may move us away from semantics entirely. The processing that occurs is not a simple mapping from natural language to formal, but constructs a new representation. We have already begun the work of interpreting a text once we focus attention on its salient aspects and render them as countable units.
Minimally, NLP is an opportunity for humanists to formalize the assumptions we bring to the table about language and culture. In terms of our research, that degree of explicitness means that we lay bare the humanistic foundations of our arguments each time we code our NLP. And therein lie the beginnings of scholarly critique and discourse.
Reference
Algee-Hewitt, Mark, Sarah Allison, Marissa Gemma, Ryan Heuser, Franco Moretti, and Hannah Walser. “Canon/Archive. Large-scale Dynamics in the Literary Field.” Literary Lab Pamphlet. 11 (2016).
Allison, Sarah, Marissa Gemma, Ryan Heuser, Franco Moretti, Amir Tevel, and Irena Yamboliev. “Style at the Scale of the Sentence.” Literary Lab Pamphlet. 5 (2013).
Bird, Steven, Ewan Klein, and Edward Loper. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit. Sebastapol, CA: O’Reilly Media, Inc. 2009.
Clement, Tanya, David Cheng, Loretta Auvil, Boris Capitanu, and Megan Monroe. “Sounding for Meaning: Using Theories of Knowledge Representation to Analyze Aural Patterns in Texts.” Digital Humanities Quarterly. 7:1 (2013).
Jockers, Matthew. “Theme.” Macroanalysis: Digital Methods and Literary History. Champaign: University of Illinois Press, 2013. 118-153.
Jockers, Matthew. “‘Secret’ Recipe for Topic Modeling Themes.” http://www.matthewjockers.net/2013/04/12/secret-recipe-for-topic-modelin…(2013).
Long, Hoyt and Richard So. “Literary Pattern Recognition: Modernism between Close Reading and Machine Learning.” Critical Inquiry. 42:4 (2016): 235-267.
Nelson, Laura K. “Political Logics as Cultural Memory: Local Continuities and Women’s Organizations in Chicago and New York City.” (under review)
Wilkens, Matthew. “The Geographic Imagination of Civil War-Era American Fiction.” American Literary History. 25:4 (2013): 803-840.
[1] In fact, there is one piece of prior knowledge required: how to open an interface in which to do the programming. This took me an embarrassingly long time to figure out when I first started! I recommend downloading the latest version of Python 3.x through the Anaconda platform and following the instructions to launch the Jupyter Notebook interface.
[2] As the authors note, they experimented with the CMU Pronouncing Dictionary specifically but selected an alternative, OpenMary, for their project. CMU is a simple (albeit very long) list of words whereas OpenMary is a suite of tools that includes the ability to guess pronunciations for words that it does not already know and to identify points of rising and falling intonation over the course of a sentence. Which tool you ultimately use for a research project will depend on the problem you wish to study.

Loved rreading this thanks