This post originally appeared on the Digital Humanities at Berkeley blog. It is the first in what became an informal series. For a brief reflection on the development of that project, see the more recent post, Reading Distant Readings.
Computers are basically magic. We turn them on and (mostly!) they do the things we tell them: open a new text document and record my grand ruminations as I type; open a web browser and help me navigate an unprecedented volume of information. Even though we tend to take them for granted, programs like Word or Firefox are extremely sophisticated in their design and implementation. Maybe we have some distant knowledge that computers store and process information as a series of zeros and ones called “binary” – you know, the numbers that stream across the screen in hacker movies – but modern computers have developed enough that the typical user has no need to understand these underlying mechanics in order to perform high level operations. Somehow, rapid computation of numbers in binary has managed to simulate the human-familar typewriter interface that I am using to compose this blog post.
There is a strange disconnect, then, when literature scholars begin to talk about using computers to “read” books. People – myself included – are often surprised or slightly confused when they first hear about these kinds of methods. When we talk about humans reading books, we refer to interpretive processes. For example, words are understood as signifiers that give access to an abstract meaning, with subtle connotations and historical contingencies. An essay makes an argument by presenting evidence and drawing conclusions, while we evaluate it as critical thinkers. These seem to rely on cognitive functions that are the nearly exclusive domain of humans, and that we, in the humanities, have spent a great deal of effort refining. Despite the magic behind our normative experience of computers, we suspect that these high-level interpretive operations lie beyond the ken of machines. We are suddenly ready to reduce computers to simple adding machines.
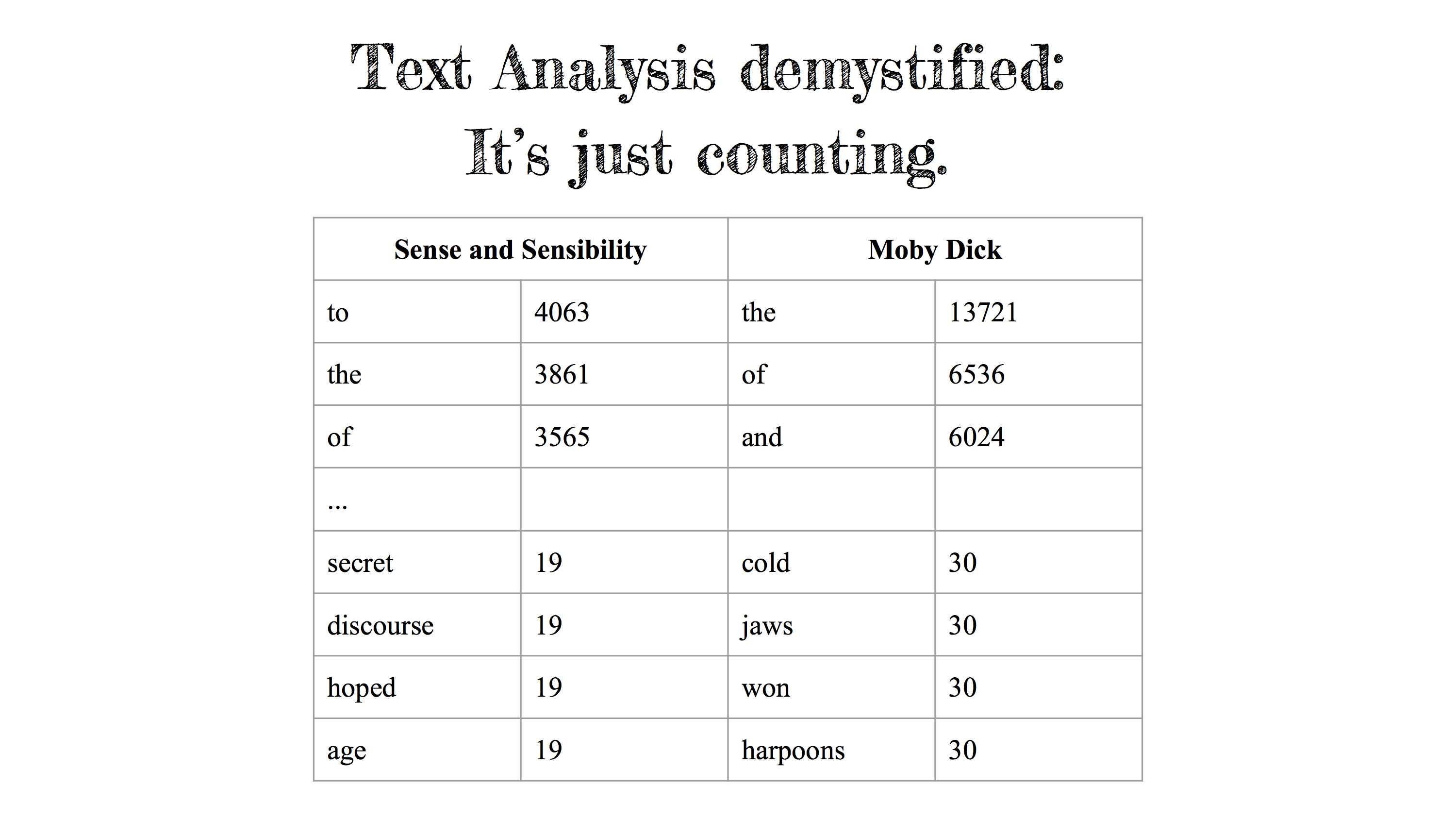
In fact, this reduction is entirely valid – since counting is really all that’s happening under the hood – but the scholars who are working on these computational methods are increasingly finding clever ways to leverage counting processes toward the kinds of cultural interpretation that interest us as humanists and that help us to rethink our assumptions about language.
Continue reading